
##2024/11/15 02:45:57:
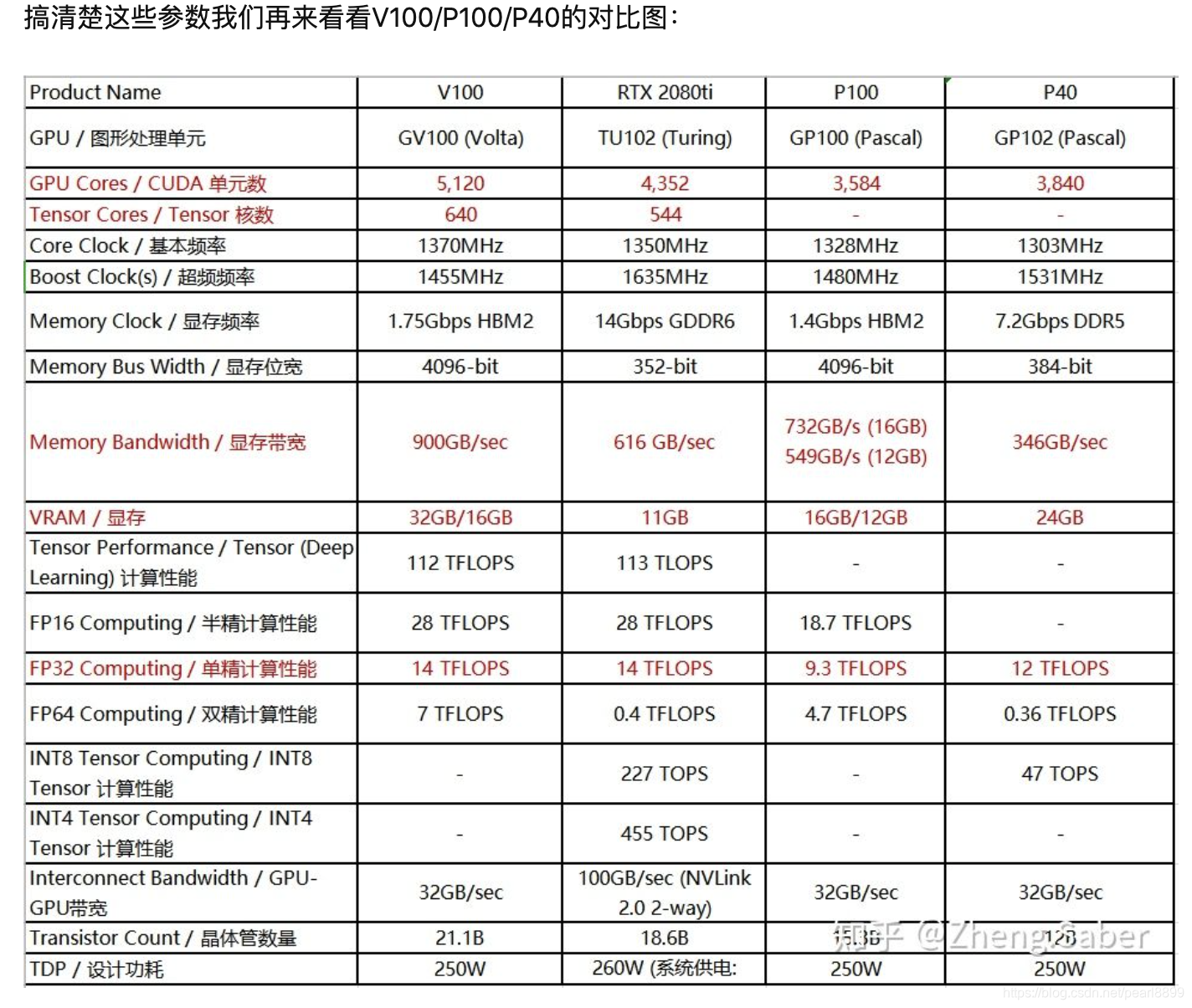
p40 p100 v100 2080ti 显卡详细的对比 #gpu
总结: 2080ti 22G 性价比最高, 其次是 v100 ,这两块 gpu 都适合低成本微调大模型
v100 tensor core fp16(半精度) 112 TFLOPS (pcie) 124 TFLOPS(nvlink) / 单精度 14 TFLOPS
2020ti fp16(半精度) 28 TFLOPS 总的 tensor 效能 130 TFLOPS
v100 2020ti 支持 tensor core
v100 volta architecture:
Tesla V100 GPU 包含 640 个 Tensor 核心:每个核心有 8 个 SM 。在 Volta GV100 中,每个 Tensor Core 每个时钟执行 64 个浮点 FMA 操作,SM 中的 8 个 Tensor Core 每个时钟总共执行 512 个 FMA 操作(或 1024 个单独的浮点操作)。
Tesla V100 的 Tensor Core 为训练和推理应用程序提供高达 125 Tensor TFLOPS 的吞吐量。与在 P100 上使用标准 FP32 操作相比,Tensor Core 在 Tesla V100 上提供高达 12 倍的峰值 TFLOPS,可应用于深度学习训练。对于深度学习推理,与 P100 上的标准 FP16 操作相比,V100 Tensor Core 的峰值 TFLOPS 高出 6 倍。
网友的评论:
- P100速度快一些,支持Float16(半精度),显存16GB。P40显存24GB,不支持float16,其它没区别。大模型且需要微调选P40,只是玩玩推理就选P100。
- Tesla P40和P100不适合训练用,我去年年底组了4*P100,同一个代码的训练速度根本比不上3090,显存吃满顶多就是3080的速度,除了显存大一点,别的没啥优点,还是太老了这卡
- 2080ti性能强的多。
- 请教一下,V100相当于数字系列哪个型号显卡的性能
2080ti差不多 - 大佬考虑过sxm2的 a100 啥的吗,一千多
- 48GB的能玩多少b的模型啊
理论上,int4的话,60B已下基本都可 - 我就是个人学习,我现在想弄8卡服务器。[发呆]
p100 与 p40 的对比:
-
英伟达 P100 和 V100 GPU 的关键性能与不同点。
https://qyzhizi.cn/img/202411150419485.png -
rtx2080ti , v100, p100 与 p40 对比
https://qyzhizi.cn/img/202411150440634.png -
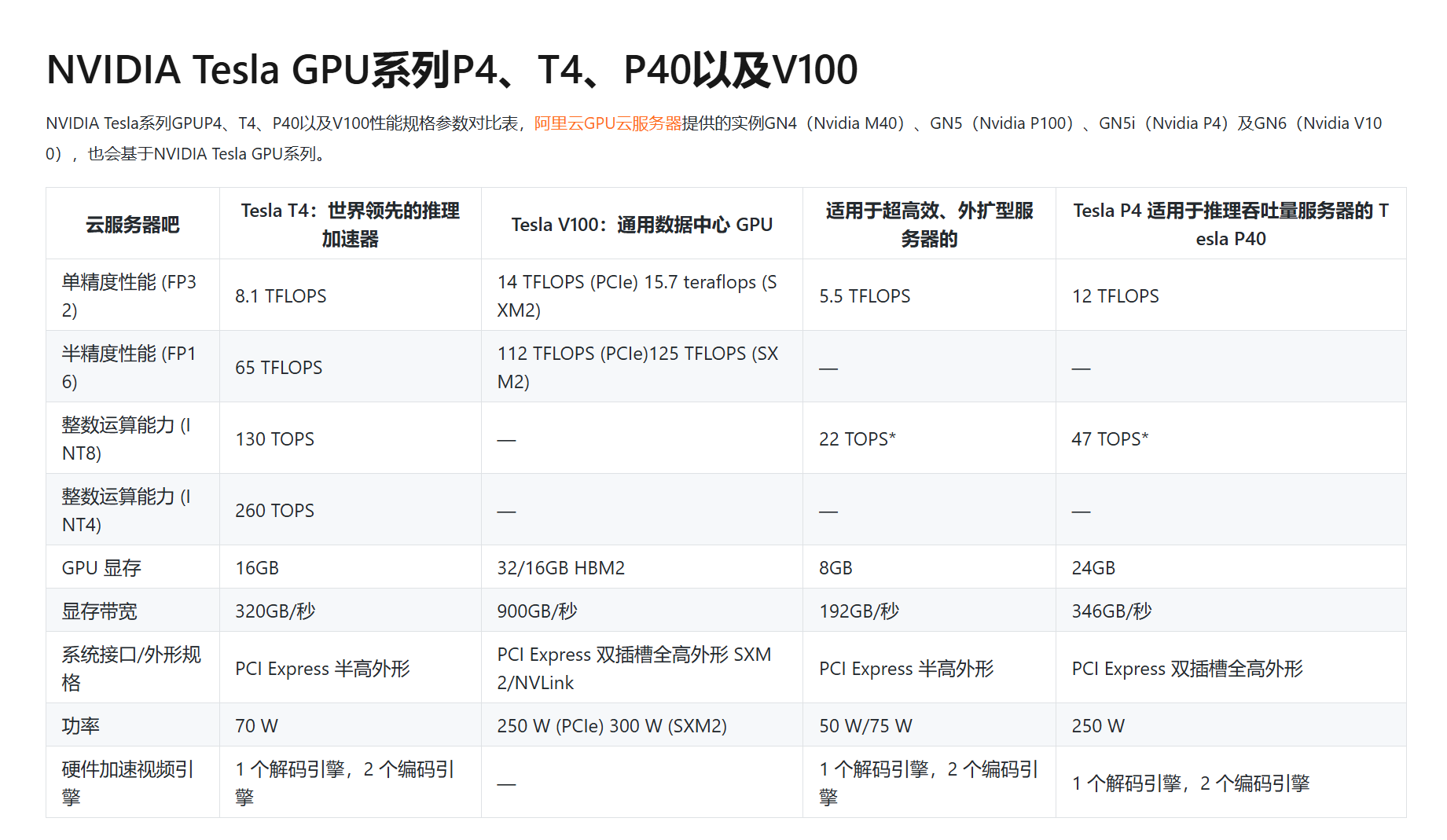
NVIDIA Tesla GPU系列P4、T4、P40以及V100 对比
https://qyzhizi.cn/img/202411150514343.png
{kind=link}
{kind=link}
{kind=link}
NVIDIA Tesla GPU系列P4、T4、P40以及V100 对比, 详细介绍如下:
-
NVIDIA TESLA V100
NVIDIA Tesla V100采用NVIDIA Volta架构,非常适合为要求极为苛刻的双精度计算工作流程提供加速,并且还是从P100升级的理想路径。该GPU的渲染性能比Tesla P100提升了高达80%,借此可缩短设计周期和上市时间。 -
Tesla V100的每个GPU均可提供125 teraflops的推理性能,配有8块Tesla V100的单个服务器可实现1 petaflop的计算性能。
-
NVIDIA TESLA P40
Tesla P40能够对组织中每个vGPU虚拟化加速图形和计算(NVIDIA CUDA® 和 OpenCL)工作负载。支持多种行业标准的2U服务器。
Tesla P40可提供出色的推理性能、INT8精度和24GB板载内存。 -
NVIDIA TESLA T4
NVIDIA Tesla T4的帧缓存高达P4的2倍,性能高达M60的2倍,对于利用NVIDIA Quadro vDWS软件开启高端3D设计和工程工作流程的用户而言,不失为一种理想的解决方案。凭借单插槽、半高外形特性以及低至70瓦的功耗,Tesla T4堪称为每个服务器节点实现最大GPU密度的绝佳之选。 -
NVIDIA TESLA P4
Tesla P4可加快任何外扩型服务器的运行速度,能效高达CPU的60倍。
##2024/11/15 22:21:29:
虽然 Tensor Cores 主要针对 FP16 运算进行了优化,但它们同样支持 INT8 和其他数据类型,能够在特定场景下提供显著的性能提升 #gpu
##Tensor Cores 支持 INT8
是的,Tensor Cores 确实主要针对 FP16(16位浮点数)运算进行了优化。但它们也支持其他数据类型,包括 INT8(8位整数)和 BF16(Brain Floating Point,16位浮点数)。以下是 Tensor Cores 对不同数据类型的支持情况的详细说明:
@@@ Tensor Cores 数据类型支持
-
FP16(16位浮点数):
- Tensor Cores 在处理 FP16 张量时提供了最高的性能加速。它们能够在每个时钟周期内执行多个 FP16 运算,从而显著提高深度学习模型的训练和推理速度。
-
INT8(8位整数):
- Tensor Cores 也优化了 INT8 运算,特别适用于深度学习推理中的量化模型。使用 INT8 可以减少内存使用和计算需求,同时保持良好的推理精度。
-
BF16(16位浮点数):
- BF16 是一种用于机器学习的浮点格式,Tensor Cores 也支持 BF16 运算,适合于某些特定的深度学习任务。
@@@ Tensor Cores 的工作原理
- 矩阵乘法:Tensor Cores 的设计目标是加速矩阵乘法运算,尤其是在深度学习中常见的操作。它们通过利用并行计算能力,能够在更短的时间内处理大量数据。
- 混合精度计算:Tensor Cores 支持混合精度计算,这意味着可以在同一计算过程中使用不同的数据类型(例如,使用 FP16 进行计算并使用 FP32 进行累加),从而优化性能和内存使用。
@ans
@@@ 实际应用
在实际应用中,开发者可以使用 TensorRT 等工具来将深度学习模型量化为 INT8,并利用 Tensor Cores 加速推理过程。这种方法在需要实时响应和高吞吐量的应用(如游戏、自动驾驶和智能监控)中非常有效。
@@@ 总结
虽然 Tensor Cores 主要针对 FP16 运算进行了优化,但它们同样支持 INT8 和其他数据类型,能够在特定场景下提供显著的性能提升。因此,在深度学习推理任务中,使用 INT8 张量并结合 Tensor Cores 是一种有效的优化策略。
##2024/10/25 04:55:50:
显卡p100 与 p40 对比
p40不支持半精度(FP16)模型训练
P100 支持混合精度计算:P100 支持 FP16(半精度)和 FP32(单精度)运算,允许在深度学习训练和推理中使用混合精度,从而加速计算并减少内存占用。
NVIDIA Tesla P100 和 NVIDIA Tesla P40 是两款主要用于深度学习、AI 推理和计算加速的专业显卡,它们有着不同的设计目标和技术参数。以下是它们的主要对比:
@@@ 1. 架构
- Tesla P100: 基于 Pascal 架构,专为高性能计算(HPC)和深度学习训练设计。
- Tesla P40: 同样基于 Pascal 架构,但更侧重于推理(inference)应用。
@@@ 2. 性能和用途
- Tesla P100: 主要用于深度学习训练,也适用于高性能计算工作负载。它有很高的计算能力和内存带宽,适合处理庞大的数据集和复杂的训练模型。
- Tesla P40: 更适合推理任务,也可以处理图像和视频处理。推理工作负载通常需要更少的计算能力,但需要更高的效率和更低的延迟。
@@@ 3. 核心配置
- Tesla P100:
- GPU 核心:3584 个 CUDA 核心
- 双精度 (FP64) 性能:4.7 TFLOPS
- 单精度 (FP32) 性能:9.3 TFLOPS
- 半精度 (FP16) 性能: 18.7 TFLOPS
- 内存:16 GB 或 12 GB HBM2
- 内存带宽:732 GB/s
- Tesla P40:
- GPU 核心:3840 个 CUDA 核心
- 单精度 (FP32) 性能:12 TFLOPS
- INT 8 性能: 47 TFLOPS
- 内存:24 GB GDDR5
- 内存带宽:346 GB/s
@ans
@@@ 4. 应用场景
- Tesla P100: 更适合深度学习训练、科学计算、数据分析等需要高计算性能的场景。
- Tesla P40: 专为推理工作负载优化,适合用在实时推理、视频分析、图像识别等领域。
@ans
@@@ 5. 功耗 - Tesla P100: 300W
- Tesla P40: 250W
@ans
@@@ 6. 价格 - Tesla P100通常价格较高,因为其侧重于训练和高性能计算。
- Tesla P40相对便宜一些,因为它专注于推理任务,功耗较低。
@ans
@@@ 总结 - 如果你关注深度学习模型训练或需要进行大量科学计算,Tesla P100 是更好的选择,因为它拥有更强大的计算能力和更高的内存带宽。
- 如果你的任务主要是推理或实时处理,Tesla P40 则会更合适,因为它在推理任务中的效率更高,且功耗相对较低。
@ans
希望这些信息对你有所帮助!
Tesla T4 P40 V100 RTX 2080 Ti 发布时间
NVIDIA Tesla T4 于 2018年9月13日 发布。 虽然发布日期是2018年9月13日,但实际生产时间可能略有前后浮动。
NVIDIA Tesla P40 于 2016年9月 发布。 和 T4 一样,实际生产时间可能略有前后浮动,但主要是在2016年下半年开始生产。
NVIDIA Tesla V100 于 2017年5月 发布。 实际生产时间可能在发布后不久开始,但主要是在2017年下半年到之后。
NVIDIA GeForce RTX 2080 Ti 于 2018年9月20日 发布。 实际生产时间应该在发布日期前后。
##2024/11/15 22:09:47:
P4 gpu 与 M40 gpu p4 适合int 8 量化推理 ,没有半精度
P4 GPU 和 M40 GPU 都是 NVIDIA 生产的图形处理单元,主要用于深度学习和高性能计算,但它们的架构、性能和应用场景有所不同。以下是它们的一些主要特点和比较:
@@@ NVIDIA P4 GPU
- 架构: P4 GPU 基于 Pascal 架构,专为推理和高效能计算设计。
- 性能: P4 的 FP16 性能达到 22 TOPS(每秒万亿次运算),适合深度学习推理任务。
- 内存: P4 通常配备 8GB GDDR5 内存。
- 功耗: P4 的最大功耗约为 75W,适合在功耗受限的环境中使用。
- 应用场景: P4 主要用于推理、视频转码和机器学习推理等任务。
@@@ NVIDIA M40 GPU
- 架构: M40 GPU 基于 Maxwell 架构,主要用于训练深度学习模型。
- 性能: M40 的 FP32 性能约为 7 TFLOPS(每秒万亿次浮点运算),适合大规模训练任务。
- 内存: M40 配备 12GB GDDR5 内存,适合处理较大的模型和数据集。
- 功耗: M40 的最大功耗约为 250W,适合高性能计算环境。
- 应用场景: M40 主要用于深度学习训练、科学计算和大规模数据处理。
@@@ 总结
- P4 GPU 更加适合推理和低功耗的应用场景,而 M40 GPU 更加适合训练深度学习模型和处理大型数据集。
- 如果你的工作负载主要是推理,P4 是更好的选择;如果你需要进行深度学习训练,M40 则更为合适。
@ans
在选择 GPU 时,建议根据具体的应用需求、功耗限制和预算进行综合考虑。
游戏 3d 渲染 使用的 cuda 是 单精度还是半精度 模式?
在游戏 3D 渲染中,使用的 CUDA 通常是单精度(FP32)模式。这是因为游戏渲染涉及大量的计算和细节处理,需要较高的精度来确保图像质量和细节的准确性。以下是一些具体的原因和背景:
@@@ 单精度(FP32) vs 半精度(FP16)
-
精度需求:
- 游戏渲染需要处理大量的几何体、光照、阴影和纹理等,这些计算通常要求较高的精度。单精度浮点数(FP32)可以提供更大的动态范围和更高的精度,适合复杂的计算任务。
-
GPU 支持:
- 现代 GPU(如 NVIDIA 的 Volta、Turing 和 Ampere 架构)均支持 FP16 计算,但在游戏开发中,FP32 仍然是主流选择。虽然 FP16 在某些情况下可以加速计算并减少内存带宽,但在图形渲染中,特别是在涉及到细致的光照和阴影计算时,FP32 更加可靠。
-
性能考虑:
- 虽然 FP16 计算在某些 GPU 上可以提供更高的性能(特别是在深度学习推理等领域),但在游戏渲染中,开发者通常选择使用 FP32 以避免潜在的精度损失。
-
现代游戏引擎:
- 许多现代游戏引擎(如 Unreal Engine 和 Unity)在渲染过程中主要使用单精度浮点数。虽然引擎可能会在某些特定的计算任务中使用 FP16(例如,在某些后处理效果中),但整体渲染流程仍然依赖于 FP32。
@@@ 结论
在游戏 3D 渲染中,CUDA 通常使用单精度(FP32)模式,以确保渲染质量和精度。虽然半精度(FP16)在某些特定场景下可能会被使用,但它并不是渲染的主要选择。
2024/11/15 21:30:20:
游戏 中的 物理模拟, 3D 渲染需要使用 tensor core 吗?, AI 驱动的渲染技术?深度学习超采样 #gpu
传统的物理渲染不需要 tensor core ,不过 dlss 这种新技术需要
在现代游戏中,AI 技术越来越多地被用于图像增强、去噪和超分辨率等任务。例如,NVIDIA 的 DLSS(深度学习超采样)技术利用深度学习来提高渲染效率和图像质量。在这种情况下,Tensor Core 可以加速这些深度学习算法的计算。
在游戏中,物理模拟和 3D 渲染并不一定需要使用 Tensor Core,但使用 Tensor Core 可以显著提高这些任务的性能,特别是在涉及复杂计算和深度学习的场景中。以下是对这两个方面的详细说明:
@@@ 物理模拟
-
传统物理模拟:
- 许多游戏使用传统的物理引擎(如 NVIDIA PhysX、Havok 等)来处理物体的碰撞、重力、运动等。这些引擎通常依赖于 CPU 和 GPU 的常规计算能力,而不需要 Tensor Core。
-
深度学习驱动的物理模拟:
- 随着 AI 和机器学习的进步,越来越多的游戏开始探索使用深度学习来改进物理模拟。例如,使用神经网络来预测物体的运动或模拟复杂的流体行为。在这种情况下,Tensor Core 可以加速深度学习模型的训练和推理,从而提高物理模拟的效率和真实性。
@@@ 3D 渲染
-
传统渲染技术:
- 3D 渲染通常依靠标准的图形处理技术,如光栅化、阴影映射和光照计算,这些任务主要由 GPU 完成,而不依赖于 Tensor Core。
-
AI 驱动的渲染技术:
- 在现代游戏中,AI 技术越来越多地被用于图像增强、去噪和超分辨率等任务。例如,NVIDIA 的 DLSS(深度学习超采样)技术利用深度学习来提高渲染效率和图像质量。在这种情况下,Tensor Core 可以加速这些深度学习算法的计算。
@@@ 总结
- 不需要:物理模拟和 3D 渲染可以在没有 Tensor Core 的情况下完成,依赖于传统的计算和图形处理技术。
- 可以加速:如果使用深度学习技术来增强物理模拟或渲染效果,Tensor Core 可以显著提高性能,尤其是在处理复杂计算时。
@ans
因此,虽然 Tensor Core 不是必需的,但在特定的应用场景中,它可以为游戏的物理模拟和 3D 渲染带来显著的性能提升。
##2024/11/15 21:30:20:
游戏 中的 物理模拟, 3D 渲染需要使用 tensor core 吗?, AI 驱动的渲染技术?深度学习超采样 #gpu
传统的物理渲染不需要 tensor core ,不过 dlss 这种新技术需要
在现代游戏中,AI 技术越来越多地被用于图像增强、去噪和超分辨率等任务。例如,NVIDIA 的 DLSS(深度学习超采样)技术利用深度学习来提高渲染效率和图像质量。在这种情况下,Tensor Core 可以加速这些深度学习算法的计算。
在游戏中,物理模拟和 3D 渲染并不一定需要使用 Tensor Core,但使用 Tensor Core 可以显著提高这些任务的性能,特别是在涉及复杂计算和深度学习的场景中。以下是对这两个方面的详细说明:
@@@ 物理模拟
-
传统物理模拟:
- 许多游戏使用传统的物理引擎(如 NVIDIA PhysX、Havok 等)来处理物体的碰撞、重力、运动等。这些引擎通常依赖于 CPU 和 GPU 的常规计算能力,而不需要 Tensor Core。
-
深度学习驱动的物理模拟:
- 随着 AI 和机器学习的进步,越来越多的游戏开始探索使用深度学习来改进物理模拟。例如,使用神经网络来预测物体的运动或模拟复杂的流体行为。在这种情况下,Tensor Core 可以加速深度学习模型的训练和推理,从而提高物理模拟的效率和真实性。
@@@ 3D 渲染
-
传统渲染技术:
- 3D 渲染通常依靠标准的图形处理技术,如光栅化、阴影映射和光照计算,这些任务主要由 GPU 完成,而不依赖于 Tensor Core。
-
AI 驱动的渲染技术:
- 在现代游戏中,AI 技术越来越多地被用于图像增强、去噪和超分辨率等任务。例如,NVIDIA 的 DLSS(深度学习超采样)技术利用深度学习来提高渲染效率和图像质量。在这种情况下,Tensor Core 可以加速这些深度学习算法的计算。
@@@ 总结
- 不需要:物理模拟和 3D 渲染可以在没有 Tensor Core 的情况下完成,依赖于传统的计算和图形处理技术。
- 可以加速:如果使用深度学习技术来增强物理模拟或渲染效果,Tensor Core 可以显著提高性能,尤其是在处理复杂计算时。
@ans
因此,虽然 Tensor Core 不是必需的,但在特定的应用场景中,它可以为游戏的物理模拟和 3D 渲染带来显著的性能提升。
2024/11/15 21:03:16:
Tensor Core 为什么比普通的 cuda 核心可以加速矩阵的运算?tensor core 的高速缓存
Tensor Core 是 NVIDIA 在其 Volta、Turing 和 Ampere 架构的 GPU 中引入的一种特殊硬件单元,旨在加速深度学习和高性能计算中的矩阵运算。Tensor Core 相比于普通的 CUDA 核心在矩阵运算方面的加速,主要体现在以下几个方面:
@@@ 1. 专门化设计
Tensor Core 设计专门用于处理矩阵乘法和卷积操作,这些操作在深度学习中非常常见。它们能够同时执行多个乘法和加法操作,利用 SIMD(单指令多数据)技术来提高计算效率。
@@@ 2. 混合精度计算
Tensor Core 支持混合精度计算,特别是 FP16(半精度浮点数)和 FP32(单精度浮点数)。在进行矩阵运算时,Tensor Core 可以使用 FP16 进行乘法操作,同时使用 FP32 进行累加。这种方法不仅加快了计算速度,还减少了内存带宽的需求,因为 FP16 占用的内存更少。
@@@ 3. 并行处理能力
Tensor Core 可以在一个时钟周期内处理多个数据元素。例如,一个 Tensor Core 可以在一个周期内执行 4x4 矩阵的乘法,这意味着它可以在更短的时间内完成大量的计算任务。相比之下,普通的 CUDA 核心在执行相同的任务时需要更多的时钟周期。
@@@ 4. 内存访问优化
Tensor Core 在内存访问模式上进行了优化,能够更高效地使用高速缓存和全局内存。这种优化使得数据能够更快地被加载和存储,从而减少了内存带宽的瓶颈。
@@@ 5. 高吞吐量
由于 Tensor Core 的设计和优化,它们能够以更高的吞吐量执行矩阵运算。对于深度学习模型,尤其是卷积神经网络(CNN)和循环神经网络(RNN),Tensor Core 可以显著提高训练和推理的速度。
@@@ 6. 适用性
Tensor Core 不仅限于深度学习,还可以用于其他需要大量矩阵运算的应用,如科学计算、图形处理等。这种广泛的适用性使得 Tensor Core 成为现代 GPU 中不可或缺的一部分。
@@@ 结论
总之,Tensor Core 通过其专门化的设计、混合精度计算、并行处理能力、内存访问优化和高吞吐量,显著提升了矩阵运算的性能。这使得在深度学习和高性能计算等领域,使用 Tensor Core 进行计算可以获得比传统 CUDA 核心更高的效率和更快的计算速度。
tensor core高速缓存
Tensor Core 的高速缓存(Cache)设计是其高效运算能力的重要组成部分。虽然 Tensor Core 本身并不直接实现高速缓存,但它的性能受益于 GPU 架构中其他层次的缓存机制。以下是与 Tensor Core 相关的高速缓存设计和优化的几个关键点:
@@@ 1. 多级缓存结构
现代 GPU 通常具有多级缓存架构,包括:
- L1 Cache:每个 Streaming Multiprocessor (SM) 通常会有自己的 L1 缓存,用于存储局部数据和指令。L1 缓存的存在可以减少对全局内存的访问延迟。
- L2 Cache:L2 缓存是共享的,服务于多个 SM。它用于存储更大范围的数据,进一步减少访问全局内存的频率。
- 共享内存:每个 SM 还具有共享内存,这是一种非常快速的存储方式,可以在同一 SM 内的线程之间共享数据。Tensor Core 可以利用共享内存来存储中间结果或输入数据,从而减少对全局内存的访问。
@ans
@@@ 2. 数据布局优化
在使用 Tensor Core 进行矩阵运算时,数据的布局(如行优先或列优先)会影响缓存的效率。为了最大化缓存的使用,通常会采用优化的数据布局,以确保数据能够有效地加载到缓存中,减少不必要的全局内存访问。
@@@ 3. 内存访问模式
Tensor Core 的设计允许它以特定的方式访问内存,以便更好地利用缓存。例如,在执行矩阵乘法时,Tensor Core 可以通过适当的内存访问模式将数据加载到缓存中,使得在计算过程中可以快速访问这些数据。
@@@ 4. 高带宽内存
Tensor Core 通常与高带宽内存(如 HBM 或 GDDR6)结合使用。这种内存类型具有较高的带宽,能够快速传输数据,进一步提高 Tensor Core 在处理大规模矩阵运算时的性能。
@@@ 5. 计算与存储的并行性
Tensor Core 设计强调计算与存储的并行性。通过在计算过程中有效地使用高速缓存,Tensor Core 可以在执行大量计算时,迅速访问所需的数据,而不会因等待数据而造成性能瓶颈。
@@@ 6. 软件优化
在编写利用 Tensor Core 的程序时,开发者可以通过选择合适的算法和数据结构来优化缓存使用。例如,使用 cuBLAS 和 cuDNN 等库时,这些库会针对 Tensor Core 和 GPU 的缓存特性进行优化,帮助开发者更高效地利用硬件。
@@@ 总结
虽然 Tensor Core 本身不直接实现高速缓存,但它的性能在很大程度上依赖于 GPU 的缓存架构和内存管理策略。通过优化数据布局、内存访问模式和利用多级缓存,Tensor Core 能够在执行矩阵运算时实现更高的性能和效率。开发者在使用 Tensor Core 时,也应考虑这些因素,以最大化其性能。
RT Core 是什么?快速实时光线追踪
##2024/11/15 07:09:12:
RT Core 专用光线追踪硬件支持快速实时光线追踪,具有物理上精确的阴影、反射、折射和全局照明。
The RTX 2080 Ti has 544 Tensor cores, RTX 2080 Ti 混合精度计算的性能
##2024/11/15 07:13:49:
#ans
RTX 2080 Ti 是 NVIDIA 的一款高性能图形处理单元(GPU),它在深度学习和高性能计算等领域表现出色,特别是在混合精度计算(Mixed Precision Computing)方面。
混合精度计算性能
混合精度计算是指同时使用单精度(FP32)和半精度(FP16)浮点数进行计算,以提高计算效率和速度,同时减少内存占用。在 RTX 2080 Ti 中,Tensor 核心专门设计用于加速这种计算。
Tensor 核心:RTX 2080 Ti 配备 544 个 Tensor 核心,这些核心能够高效地执行矩阵运算,特别是用于深度学习模型的训练和推理。Tensor 核心支持 FP16、FP32 以及 INT8 精度的计算。
性能指标:在混合精度计算中,RTX 2080 Ti 的理论性能可以达到:
FP16 性能:约 130 TFLOPS(万亿次浮点运算每秒)
FP32 性能:约 13.4 TFLOPS
这些性能指标使得 RTX 2080 Ti 在训练深度神经网络时能够显著提高速度,尤其是在使用深度学习框架(如 TensorFlow 和 PyTorch)时,能够充分利用 Tensor 核心的加速能力。
结论
总体来说,RTX 2080 Ti 在混合精度计算方面提供了强大的性能,适合用于深度学习和其他需要高计算能力的应用。通过利用其 Tensor 核心,用户可以在训练和推理过程中获得更快的计算速度和更高的效率。
RTX 2080 Ti 除了 tensor core 是不是还额外带有 fp16 精度的运算
#ans
是的,RTX 2080 Ti 除了配备 Tensor 核心外,还支持 FP16(半精度浮点数)运算。FP16 运算是通过 CUDA 核心进行的,这使得 RTX 2080 Ti 在处理 FP16 计算时能够提供更高的性能和更低的内存占用。
@@@ FP16 运算的优势
- 内存带宽:FP16 数据占用的内存空间是 FP32 的一半,这意味着在相同的内存带宽下,可以传输更多的数据。这对于大规模深度学习模型的训练和推理是非常有利的。
RTX 2080TI Tensor Cores 的计算能力
#ans
NVIDIA GeForce RTX 2080 Ti 是一款高性能显卡,特别适合深度学习和计算密集型任务。其核心特性之一是集成的 Tensor Cores,这些专用硬件单元显著提升了深度学习的推理和训练性能。
@@ Tensor Cores 的计算能力
@@@ 结构与性能
RTX 2080 Ti 配备了 544 个 Tensor Cores,每个 SM(流处理器组)中有8个 Tensor Core。这使得该显卡的 Tensor FLOPS(每秒浮点运算次数)达到近 114 TFLOPS,这在深度学习任务中非常有效[1][2]。相较于前代 GTX 1080 Ti,RTX 2080 Ti 在 Tensor Core 性能上有显著提升,使其在处理复杂的矩阵运算时表现更佳。
@@@ 深度学习应用
Tensor Cores 特别适用于需要大量矩阵乘法的深度学习模型,如卷积神经网络(CNN)和递归神经网络(RNN)。使用 Tensor Cores 进行16位浮点数计算,可以在相同内存带宽下传输更多数据,从而提高计算效率。研究表明,使用 Tensor Cores 的卷积网络可以实现 30% 到 100% 的速度提升,而 LSTM 网络则可加速 20% 到 60%[3][4]。
@@@ 性能比较
在实际应用中,RTX 2080 Ti 的性能在深度学习领域被广泛认可。例如,与 GTX 1080 Ti 相比,RTX 2080 Ti 在推理性能上提升了约 33%。即使与两张 GTX 1080 Ti 的 SLI 配置相比,单卡 RTX 2080 Ti 的性能也仅落后约 20%,显示出其高性价比[1][2]。
@@@ 总结
总体来看,NVIDIA GeForce RTX 2080 Ti 的 Tensor Cores 为深度学习和其他计算密集型任务提供了强大的支持。凭借其高达 114 TFLOPS 的计算能力和对16位浮点数的优化,该显卡在市场上仍然是一个非常有竞争力的选择,尤其是在需要高效处理大规模数据时。
Citations:
[1] http://www.alphalook.com/2018/11/19/nvidia-geforce-rtx-2080ti/
[2] https://blog.csdn.net/nielinyuan1466/article/details/131803832
[3] https://cloud.tencent.com/developer/article/1346454
[4] https://liuziyang1106.github.io/work/2021/03/24/deep-learning-GPU-benchmark/
[5] https://www.pcpop.com/article/5042355_all.shtml
[6] https://www.evolife.cn/computer/188562.html
[7] https://www.nvidia.cn/geforce/graphics-cards/rtx-2080-ti/
[8] https://blog.csdn.net/m0_37909240/article/details/107862142
-
计算速度:在支持 FP16 运算的情况下,RTX 2080 Ti 可以在某些情况下实现更高的计算速度,尤其是在深度学习和计算机视觉等应用中。
-
混合精度训练:在深度学习中,使用混合精度训练(Mixed Precision Training)可以同时利用 FP16 和 FP32 的优势。通过将大部分计算使用 FP16 进行加速,同时保留关键计算(如梯度累积)使用 FP32,可以在不显著降低模型精度的情况下提高训练速度。
@@@ 总结
因此,RTX 2080 Ti 不仅具备 Tensor 核心来加速 FP16 运算,同时也支持通过 CUDA 核心进行 FP16 计算。这使得它在深度学习和高性能计算任务中表现出色,能够有效利用混合精度计算的优势。
使用半精度混合训练满足的条件 gpu, 判断你的GPU是否支持FP16:构拥有Tensor Core的GPU(2080Ti、Titan、Tesla等),不支持的(Pascal系列)就不建议折腾了
在最近在apex使用中的踩过的所有的坑,由于apex报错并不明显,常常debug得让人很沮丧,但只要注意到以下的点,95%的情况都可以畅通无阻了:
判断你的GPU是否支持FP16:构拥有Tensor Core的GPU(2080Ti、Titan、Tesla等),不支持的(Pascal系列)就不建议折腾了。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/pearl8899/article/details/112875396
Tensor Core gpu
Tensor Core:我们知道在深度学习中大量的运算都是在高维矩阵(张量 Tensor)间进行的,Tensor Core可以让tensor的计算速度急速上升。Tensor Core专业执行矩阵数学运算,适用于深度学习和某些类型的HPC。Tensor Core执行融合乘法加法,其中两个44 FP16矩阵相乘,然后将结果添加到44 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。NVIDIA将Tensor Core进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。碰巧的是,Tensor Core所做的这种运算在深度学习训练和推理中很常见。
2024/11/15 04:14:34:
tensor core 似乎只是针对 矩阵乘法 矩阵乘法仅占 LSTM 总体训练时间的 20%, 但是对大模型比较有用,大模型可以更好的利用 tensor core
这一令人失望的性能比可能是因为 V100 中强大的 Tensor Cores 只能用于半精度(FP16)或混合精度的矩阵乘法运算。而对这两个模型进行分析的结果表示矩阵乘法仅占 LSTM 总体训练时间的 20%,所占 RNN 总体训练时间则更低。这与擅长于处理图像数据的卷积神经网络形成鲜明对比,它们的运行时间由大量的矩阵乘法支配,因此能更加充分地利用 Tensor Cores 的计算资源。
虽然 V100 与 P100 相比显示出强大的硬件性能提升,但深度学习中擅于处理时序数据的循环神经网络无法充分利用 V100 这种专门化地硬件加速,因此它只能获得有限的性能提升。
使用 v100 训练大模型是,这种情况是否会好很多?:
使用 V100 训练大模型时,性能提升的情况可能会有所改善,但仍然受到一些因素的影响。
-
模型架构的影响:如果大模型包含大量的矩阵乘法操作(例如在某些变体的 Transformer 模型中),那么 V100 的 Tensor Cores 能够更有效地利用,从而实现更好的性能提升。相比之下,LSTM 和其他 RNN 模型的矩阵乘法占比相对较小,因此即使在更大的模型中,性能提升也可能有限。
-
大模型的并行化:大模型通常可以更好地进行数据并行或模型并行,这样可以充分利用 V100 的多 GPU 配置,进一步提升训练速度。对于大规模模型,尤其是 Transformer 这样的架构,能够更好地利用 GPU 的计算能力。
-
混合精度训练:V100 支持混合精度训练(FP16),这可以显著提高训练速度并减少显存使用。如果大模型能够有效利用这种训练方式,可能会获得更好的性能。
-
内存带宽和计算密集度:大模型通常需要更高的内存带宽和计算能力。V100 在这方面的优势可能会使得大模型的训练速度更快,尤其是在处理大批量数据时。
总结来说,尽管 V100 在硬件性能上有显著提升,但对于 LSTM 和 RNN 模型,性能提升仍可能受到限制。然而,如果训练的是大规模的、计算密集型的模型(如 Transformer),那么 V100 的优势将会更加明显,性能提升可能会更好。
chatgpt 回答
是的,Tensor Core 主要是针对矩阵运算进行优化的,尤其是矩阵乘法(如 GEMM,General Matrix Multiplication)。在大规模语言模型(LLM)中,矩阵乘法确实是非常常见的操作。这些模型通常会涉及到大量的线性代数运算,特别是在前向传播和反向传播过程中。
以下是一些 LLM 中矩阵乘法的具体应用:
-
嵌入层:在输入层,词嵌入(word embeddings)通常涉及矩阵乘法,将词索引映射到高维向量空间。
-
注意力机制:在 Transformer 架构中,注意力机制依赖于矩阵乘法来计算查询、键和值的组合,这些操作通常需要进行多次矩阵乘法。
-
前馈神经网络:在 Transformer 的每个层中,前馈神经网络部分也涉及到矩阵乘法。
-
模型参数更新:在训练过程中,反向传播算法会涉及到大量的矩阵运算,以更新模型参数。
由于 LLM 通常具有非常大的参数量和复杂的网络结构,使用 Tensor Core 可以显著加速这些矩阵运算,尤其是在 GPU 上。Tensor Core 通过使用混合精度(如 FP16 和 BF16)来提高计算效率,同时保持模型的精度,这使得它们特别适合深度学习任务。
总的来说,矩阵乘法在 LLM 中占据了重要地位,因此 Tensor Core 的优化对提升 LLM 的训练和推理速度非常有帮助。